
Sulla lotta all’evasione il governo prova a dare una sterzata decisa. L’incrocio delle banche dati del Fisco per scovare i contribuenti a più alto rischio evasione sta per partire. E questa dovrebbe essere la volta buona. Sono ormai due anni che l’arma finale anti-evasione è pronta, ma non riesce a essere calata a terra per i paletti posti dal garante della Privacy sull’utilizzo di un numero elevatissimo di banche dati nella disponibilità dell’Agenzia delle Entrate e della Guardia di Finanza. Il dossier, tuttavia, si sarebbe sbloccato.
Nell’ultimo consiglio dei ministri, il sottosegretario alla Presidenza del consiglio, Roberto Garofoli, ha fatto il punto, ministero per ministero, sull’attuazione del Pnrr. Al momento di indicare gli obiettivi per fine giugno del ministero dell’Economia, ha spiegato che «è stato trasmesso al Garante per la privacy lo schema di decreto ministeriale recante le procedure per la pseudo-anonimizzazione dei dati da parte dell’Agenzia delle Entrate, ai fini dell’acquisizione del relativo parere». Ed in effetti l’Authority, secondo quanto ricostruito dal Messaggero, avrebbe ricevuto la nuova bozza del decreto proprio giovedì 26 maggio.
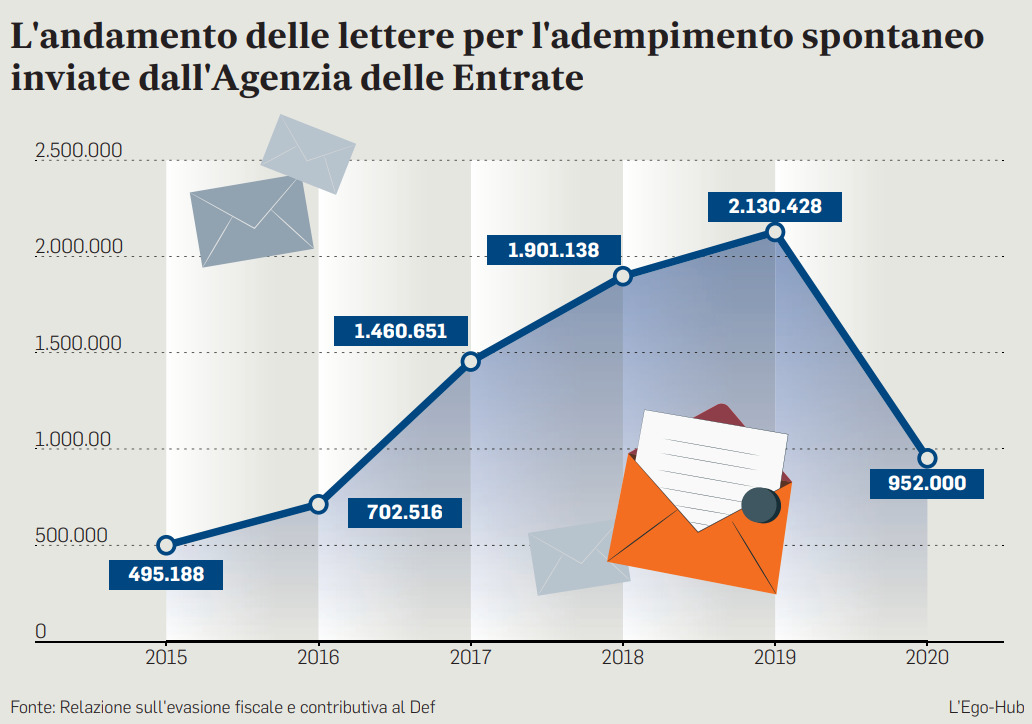
L’aumento del 15 per cento delle lettere deve essere calcolato rispetto al 2019, quando ne furono inviate 2,13 milioni che permisero di incassare 1,2 miliardi di euro. Quest’anno, dunque, dovranno partire 2,5 milioni di lettere. Per questo l’Agenzia delle Entrate e la Guardia di finanza hanno bisogno il prima possibile di poter incrociare i dati. In modo da colpire i bersagli senza errori. L’elenco delle banche dati disponibili per incrociare i dati, come detto, è lungo: conti correnti, vecchi accertamenti, carte di credito, bollette elettriche e del gas, spese per lo sport, registri immobiliari e mobiliari e, persino, le spese sanitarie. Proprio sull’uso di queste ultime il garante aveva posto seri dubbi di rispetto della privacy per cui, nella nuova versione del decreto, potrebbero essere escluse.
Ma come funzionerà l’algortimo del Fisco? Grazie all’intelligenza artificiale verranno creati due “dataset”, in sostanza due liste di contribuenti. La prima di “analisi”, servirà a individuare se ci sono platee di contribuenti che presentano un rischio di evasione superiore agli altri. Poi ci sarà un dataset di “controllo”. In questo elenco saranno inseriti i contribuenti che presentano uno o più rischi fiscali. Per evitare rischi legati alla privacy, questa lista non sarà visibile con i nomi reali dei contribuenti, ma con degli pseudonomi. Solo al momento dell’invio della lettera di compliance o dell’accertamento, si potrà svelare il nome del contribuente.
Nelle prossime settimane inoltre, potrebbe arrivare anche un nuovo decreto legge di semplificazione fiscale. Un provvedimento all’interno del quale potrebbero trovare posto anche una serie di rafforzamenti dello strumento della lettera di compliance in modo da accelerare il recupero delle somme contestate ai contribuenti.